 systems")
While it is true that the field of Artificial Intelligence, including the application of Large Language Models (LLMs), has come a long way, the fact remains that LLMs possess one major drawback: they are essentially frozen in time. They can become obsolete, inaccurate, and may even provide misleading information if the question asked is outside the parameters of the model.
Retrieval-Augmented Generation (RAG) is built to address this difficulty. But the hard truth is one that many organizations learn the hard way: RAG is only as good as the data it is fed.
In this blog, we aim to show how effective data management can be the hidden force behind the success of RAG in every single way.
Why is data quality essential in RAG, and how does it work?

Retrieval-Augmented Generation leverages external data sources to provide contextual grounding, resulting in responses that are more reliable and informative. The system doesn’t depend on a model’s prior knowledge. Instead, it finds the most relevant documents, records, or data snippets, which lets it base the AI’s output on real-world information.
In theory, this mechanism is very strong. But in practice, the retrieval step depends completely on how good, structured, and organized the data is. If your data is poorly tagged, duplicated, or outdated, it can produce unreliable or low-quality outputs. When data is unstructured and inconsistent, retrieval algorithms must work harder, which can negatively impact the quality of results. Siloed data prevents the system from forming a comprehensive view necessary to address complex queries.
Effective data management is what bridges the gap between a RAG system that sounds plausible and one that is reliably accurate.
Understanding the data layer behind high-performing RAG systems
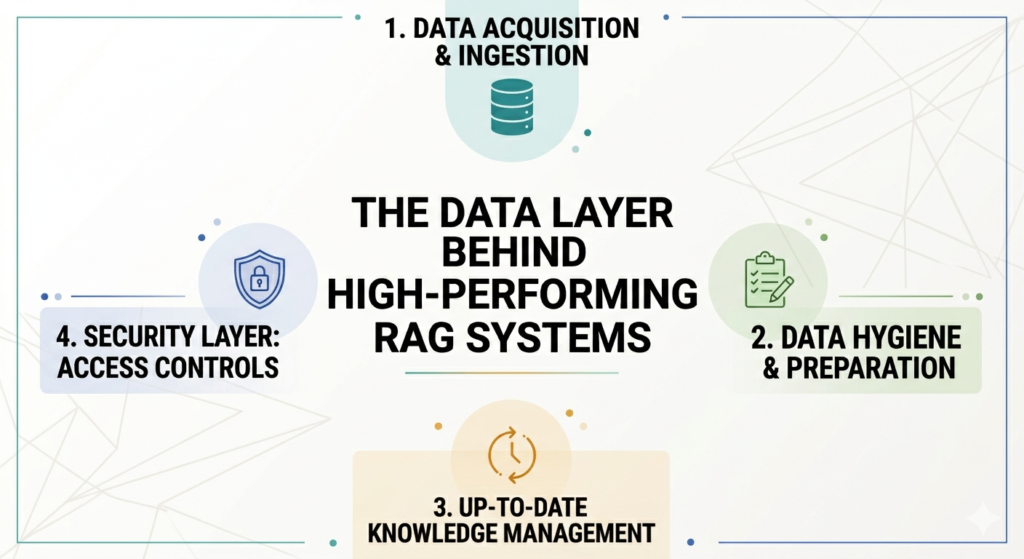
1. Clean data enables contextual precision
One of the most important aspects of RAG’s strengths is that it offers responses that are extremely relevant to the context. An efficient RAG system should be able to retrieve the precise document within an organization that outlines the company’s policy regarding remote work when an employee queries about it. It should not retrieve an old document or one related to another department.
This level of precision can only be attained through proper data curation, classification, and maintenance. For an efficient data retrieval system to display accurate results for a given query, proper data management techniques like metadata tagging, document versioning, and de-duplication must be in place. Even highly efficient retrieval systems can produce suboptimal results if effective data management practices are not in place.
2. Up-to-date data keeps RAG reliable
RAG’s key advantage over static LLMs is its ability to incorporate real-time or recently updated information. This makes it exceptionally valuable in fast-moving domains, like customer support, financial services, compliance, and healthcare, where the data is constantly changing.
However, keeping data truly real-time isn’t automatic. For RAG to consistently surface current information, organizations need robust data pipelines that ingest, refresh, and retire data on a continuous basis. This includes establishing data governance strategy and policies that define how frequently knowledge bases are updated and what triggers a document to be archived or replaced.
Without these measures, a RAG system may confidently retrieve a policy that was replaced six months ago or a product specification that doesn’t match what’s currently available. The “real-time” promise of RAG is only possible if there is effective data lifecycle management in place.
3. Data access controls ensure secure and relevant retrieval
In most organizations, information isn’t meant to be universally accessible. A RAG system should take this into account by returning not just relevant results, but results that the user is actually permitted to see.
To make this work, access controls need to be built into the data layer itself. This can include role-based permissions, document-level restrictions, and clear separation between different types of data. Without these in place, the system risks exposing sensitive information, like HR records or financial details, to the wrong audience.
When access rules are properly enforced, they do more than just protect data. They also improve the quality of responses by limiting retrieval to information that is both relevant and appropriate for the user’s role.
In regulated environments, especially, this becomes critical. A well-managed data layer ensures that RAG systems can be used confidently in real-world settings, where both accuracy and data privacy matter.
4. Good data governance unlocks enterprise-wide productivity
RAG’s greatest promise for organizations is the democratization of knowledge, giving every team member fast, accurate access to the information they need without requiring them to be subject-matter experts. This is where master data management and RAG together create a true productivity multiplier.
A strong governance framework supports scalable knowledge sharing, enabling cross-functional collaboration and reducing dependency on isolated subject-matter expertise. Compliance documents, technical guides, customer data, and internal research can become actionable tools, not hidden treasures. Time is no longer spent searching for the right data, nor is time spent verifying the data.
The inverse is equally true: organizations with fragmented data practices will find that RAG amplifies their inconsistencies, making bad information more accessible rather than making good information more useful.
Building the foundation: Where to start
Organizations that wish to realize the best ROI on their RAG systems will regard data management as a first-class initiative, not an afterthought. This includes:
* Auditing knowledge bases to ensure that gaps, duplication, and obsolescence are addressed
* Developing standards for metadata to enhance discoverability and classifiability of content
* Developing data governance models that establish data ownership and update cycles
* Developing data pipelines that ensure knowledge bases are kept current and relevant as conditions change
* Developing access control systems that enable RAG systems to access data securely throughout the organization
Don’t just deploy AI, Ground it.
RAG effectiveness begins with quality data. Those businesses that invest in clean, structured, and well-governed data sets will find RAG delivers on the promise of accurate, informed, and trustworthy answers through the power of AI. Those who do not will simply spread bad data faster.
Competitive advantage in the AI-driven world belongs to those businesses that take master data management as seriously as the businesses they compete against. This is where Mobius can help. Our full-service solutions, including intelligent data extraction, quality governance, seamless integration, and warehousing, can provide your RAG infrastructure with the support it needs to thrive.
Ready to retrieve the full potential of your business’s AI investments? Talk to a Mobius expert today.
Read AI-generated summary
- In this blog, we aim to show how effective data management can be the hidden force behind the success of RAG in every single way.
- Effective data management is what bridges the gap between a RAG system that sounds plausible and one that is reliably accurate.
- An efficient RAG system should be able to retrieve the precise document within an organization that outlines the company’s policy regarding remote work when an employee queries about it.
- For an efficient data retrieval system to display accurate results for a given query, proper data management techniques like metadata tagging, document versioning, and de-duplication must be in place.
- Without these measures, a RAG system may confidently retrieve a policy that was replaced six months ago or a product specification that doesn’t match what’s currently available.



