
This blog details a document, page indexing and retrieval solution using ElasticSearch and is co-authored by Vignesh K, Ida Jessie Sagina
Did you see Google Trends’ Frightgeist 2017? Wonder Woman tops the list of famous costumes this Halloween season. You can also find the trending costumes specific to your locality and Voila! You can easily pick the most relevant and outstanding outfit of the season.
Unlike momentary Halloween party fame, being popular and standing out in an ocean of competitors matters big time for businesses large and small who expect actionable insights from the changing market trends. Business intelligence companies cater to them by poring over scores of documents to provide accurate and timely market and analytics data. They turn to web extraction and data management solutions to handle the vast amounts of data.
In this article, we share an adaptable solution for document and page level retrieval using ElasticSearch, that we arrived at while extending our services to an energy sector data analysis company.
The business need :
A UK based energy intelligence company required a document store database to hold analysis and research documents in the form of PDF’s, Excel, text file etc., They also wanted to tag those documents both document level and page level and retrieve them based on the tags and the content of the documents. Hence two kinds of retrieval were needed –
- Page level Retrieval – To retrieve specific pages that matched the search content and tags.
- Document Level Retrieval – To retrieve an entire document based on the searched content and tags.
Why ElasticSearch to meet our challenge?
There were solutions out in the market for document level tagging and retrievals like Aleph and OverviewDocs. But a page level retrieval was not part of their kitty.
That’s when we turned to an unexplored feature of ElasticSearch. Before we dive into the nitty-gritty bits of the solution, here’s a quick heads up on what ElasticSearch does.
Likeable Features of ElasticSearch:
Guys at Elasticsearch define their product as an “in-house google” which explains it all. To elaborate further –
- It’s an open-source, broadly-distributable, readily-scalable, enterprise-grade search engine.
- Can power extremely fast full-text searches for data discovery applications.
- Multiple configurations and variations available to tag and index documents in ElasticSearch like PDF’s, Excel etc.,
- Capable to handle up to Petabytes of data and scalable to a large extent.
- Supremely fast and accurate.
Narrowed down to ElasticSearch but what next?
Features and capabilities of ElasticSearch made it a very viable answer to our business requirement but there was a catch here. Indexing in the document level was a common feature while page level indexing was not available by default.
We had to build a tailor-made solution for page level retrieval.
How we developed a customised solution with ElasticSearch :
We adopted the Parent-Child relationship in ElasticSearch to cater to our needs. How would this work?
- In the Parent, Document meta information and Document Tags can be saved.
- The child can refer to the Parent type and can also index Page tags, Page content and page level Page meta information.
An example is shown below.
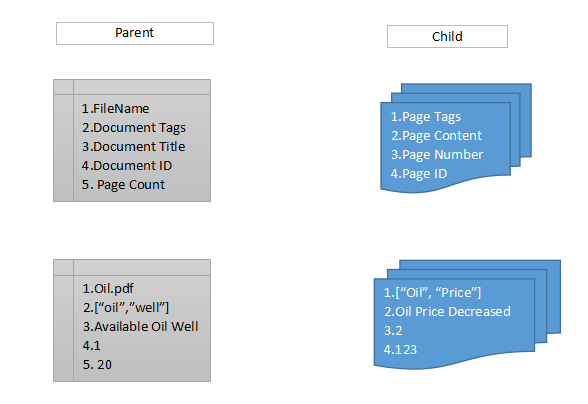
- By this way, we could index both Document and Page level tags and also retrieve them at the document level and page level.
While ElasticSearch serves as the core search engine, to facilitate splitting, encoding and merging of pages during retrieval calls for a proper document database system.
ElasticSearch Document Database Architecture:
The below architecture was employed with ElasticSearch as the core.
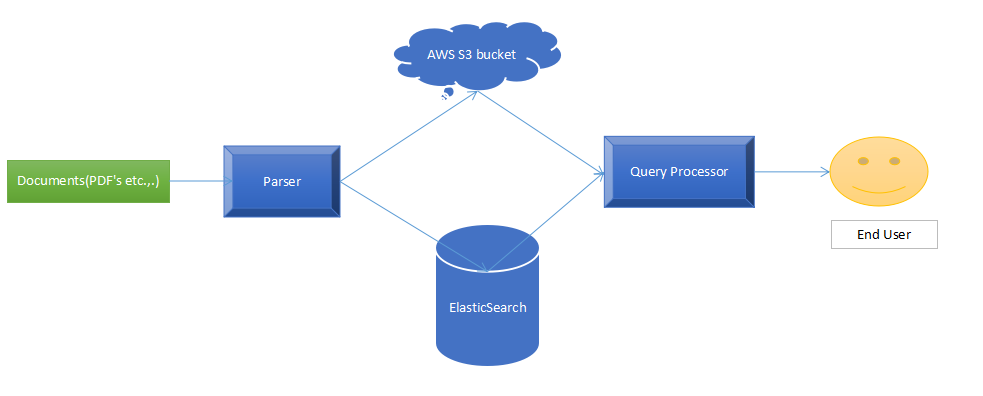
The architecture comprises of four main parts –
- Parser: This component parses the documents, splits them, encodes them to base64 and pushes actual page without base64 encode to AWS S3 and encoded page to ElasticSearch along with AWS s3 location.
- AWS S3 Storage: Both the document and pages of the document are saved here for later retrieval by the user.This is done so that when a user searches for a document, we initially hit the ElasticSearch, fetch the meta information about the document from there and then retrieve the corresponding document/page from AWS S3.
- ElasticSearch: ElasticSearch serves as the core search engine for searching tags, documents, and pages.
- Query Processor: The end user will query the document from here. When a search query is given, the query processor would hit the ElasticSearch, get the meta information from there and then retrieves the actual document/page from S3. This is done to attain maximum speed and performance. The result will then be published to the end user.
Technical Implementation of the solution:
The retrieval process done by the ElasticSearch engine can be broadly broken down into the following steps –
- Plugin Creation – The first step to create the database in ElasticSearch is to convert the pages into base64 encoded content. A plugin is to be created to ingest base64 encoded PDF, word, etc., and index them to ElasticSearch.
- Index Creation – Next an index is to be created to index the document. Since there is no special search requirement, a default index with parent and child mapping is to be formed.
- Indexing parent document – When a new document is added, we have to index document level details in parent document using an API call.
- Indexing child document – Once the parent is created, the pages and the related information in the pages can be indexed using another API.
- Retrieving documents by query – A document can be queried based on text, title, and tags and a common method can be used for all.
Possible Search Types in ElasticSearch :
There are many search types in ElasticSearch by default. Below are a few of them.
| Type of Search | Description | Search Terms | Resultant Documents |
| Term contain search | Will match documents which contains any of the given input terms –
In any order |
“query”: “oil sale” |
|
| Term Contain with match criteria | Will match documents which contain any of the given input terms and it should match at least the given number of terms in minimum match criteria
In any order |
“query”: “oil sale”
AND “minimum_should_match”:”2” |
|
| Contain search | Will match documents which contain all of the given input terms –
In any order |
“query”: “Saudi Arabia oil”
AND “minimum_should_match”:”100%” |
Saudi Arabia, in the fields of integrated services for oil |
| Combined search | Can combine multiple searches and can perform AND/OR kind of searches | Title “query”: “Oil Mining”
AND Country “query”:”Saudi” |
“Title”: “Oil Mining in Saudi”
“Country”:”Saudi” |
| Phrase search | Will match documents which contain the full search query
In that order |
“Phrase_Query”:”petroleum gas” | 1.liquified petroleum gas |
| Proximity Search | Will match documents which contain search query in given order with limited terms in between as specified in search
In that order |
“Phrase_Query”: “petroleum gas”
AND “slop”:1 |
1.total petroleum liquids gas
2.liquefied petroleum gas |
| Fuzzy Match | Will match documents with search query by allowing to match with slight changes in document | “Fuzzy_Query”: “Oils”
AND “Fuzziness”:1 |
“Oills wells” Will not match “Oil” since it requires 2 changes |
| Phonetic Match | Will match documents which sound similar to search query | “Phonetic-Query”:”Jahnnie Smeeth” |
|
| N-gram Match | Will find documents which partially matches | “N-gram-Query”:”Drown”
AND “Gram”: “3” |
|
How we adapted the phrase search:
Our business requirement was to perform a phrase search for content matching and the exact match for tag matching.
The solution outlined above is used as our document store database for document/page retrieval and it has a stunning response time that varies from few milliseconds to seconds. Though the current scope of the solution is limited to PDF documents, we are planning to extend the same to other document types like spreadsheets and text files.
Do you have another or similar workaround for document retrieval? Share your ideas with us by commenting on this blog or mail us at [email protected].
Read AI-generated summary
- In this article, we share an adaptable solution for document and page level retrieval using ElasticSearch, that we arrived at while extending our services to an energy sector data analysis company.
- , They also wanted to tag those documents both document level and page level and retrieve them based on the tags and the content of the documents.
- By this way, we could index both Document and Page level tags and also retrieve them at the document level and page level.
- While ElasticSearch serves as the core search engine, to facilitate splitting, encoding and merging of pages during retrieval calls for a proper document database system.
- This is done so that when a user searches for a document, we initially hit the ElasticSearch, fetch the meta information about the document from there and then retrieve the corresponding document/page from AWS S3.


 systems")
