
Ever since machine learning and data science took the world by storm, researchers and businesses alike are on the lookout for more data and the hunt for data is on from unconventional data sources like the Internet.
Being an extremely curious data scientist or an entrepreneur high on innovation, you don’t want to lose out on the growth opportunities lying untapped in the public web. Here’s where the art of web scraping comes to your rescue in mining super-cool insights with bright business returns.
Now that the usefulness of web scraping is accepted beyond doubt, how should you go about scraping data and more importantly what’s the best web scraping tool that could get your job done?
So first, pick the right web scraping approach
The purpose and resources you have in hand best determine the approach you take for a scraping project. Web scraping as we have seen it evolve in the past 2 decades, is majorly done in the following ways –
- Build your very own scraper from scratch – This is for code-savvy folks who love experimenting with site layouts and tackle blockage problems and are well-versed in any programming language like Python, R or Perl. Just like their routine programming for any data science project, a student or researcher can easily build their scraping solution with open-source frameworks like Python-based Scrapy or the rvest package, RCrawler in R.
- Developer-friendly tools to host efficient scrapers – Web scraping tools suitable for developers mostly, where they can construct custom scraping agents with programming logic in a visual manner. You can equate these tools to the Eclipse IDE for Java EE applications. Provisions to rotate IPs, host agents, and parse data are available in this range for personalization.
- DIY Point-and-click web scraping tools for the no-coders – To the self-confessed non-techie with no coding knowledge, there’s a bunch of visually appealing point and click tools that help you build sales list or populate product information for your catalog with zero manual scripting.
- Outsourcing the entire web scraping project – For enterprises that look for extensively scaled scraping or time-pressed projects where you don’t have a team of developers to put together a scraping solution, web scraping services come to the rescue.
If you are going with the tools, then here are the advantages and drawbacks of popular web scraping tools that fall in the 2nd and 3rd category.
DIY point-and-click web scraping tools for the no-coders
Import.io
Truly a killer in the DIY tools category, Import.io provides a way for anyone with a web data need to extract information with a very user-friendly, intuitive, and interactive interface. The cloud-based scraping platform can structure data found behind images, login screen and hundreds of web pages with absolutely no coding. Monitoring website changes and the ability to integrate with a number of reporting tools and apps make it a great option for enterprises with a pressing scraping need.
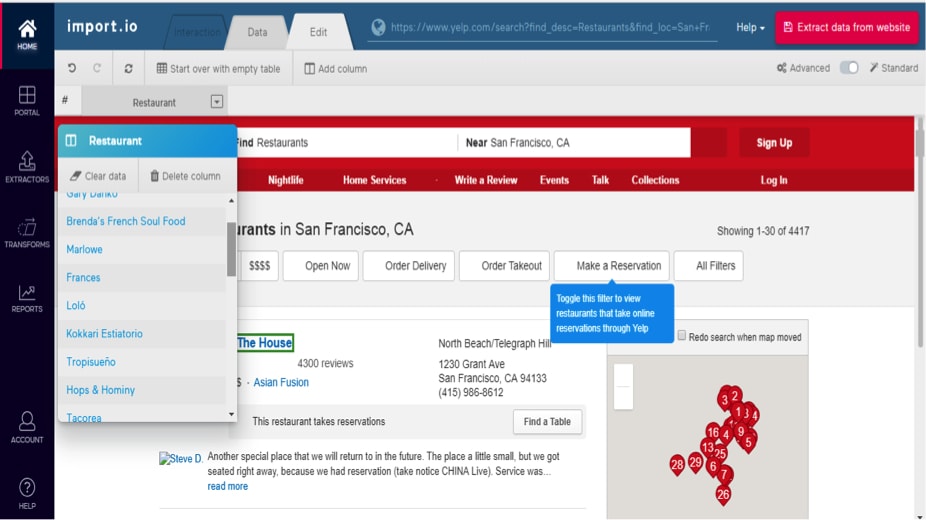
Pros:
- A simple and light-weight UI that works well for non-coders looking to build their list of prospects or track price changes.
- It’s a viable option for scraping at a reasonable speed efficiently from different websites concurrently.
Cons:
If this sounds like your Aha product then there should be just one thing stopping you from trying it – the PRICE! While they had adopted a freemium model earlier, it’s no longer available (basic plan begins at $299/month) and scraping more pages equals scraping more dollars off your pocket.
Dexi.io
Earlier called CloudScrape, Dexi.io is another visually stunning extraction automation tool positioned for commercial purposes and is available as a hassle-free browser app. Dexi has provisions for creating robots that can work as an extractor or crawler or perform ETL data cleansing tasks after extraction in the form of Dexi Pipes. The powerful scraping tool gives suggestions after data selection on the webpage for intelligent extraction features that resolves pagination issues, performs extraction in a loop and takes screenshots of web pages.
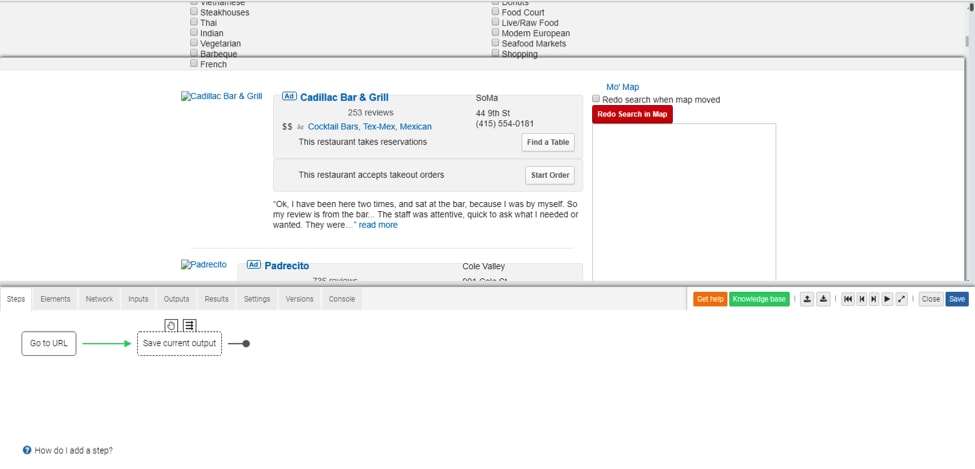
Pros:
- There are no tough set-up routines that you’ve got to follow. Sign up and the browser app opens for you to create your robot. Their awesome support team will help you with the bot creation in case you hit a roadblock.
- For a commercial tool, the standard plan priced at $119/month (for small projects) is very reasonable and the professional plan would be apt for a larger business needs.
Cons:
- The concept of add-ons in Dexi.io though attractive at first becomes a handful to maintain as the add-ons increase and so does the cost for any add-on in the store.
- There are slight murmurs and grunts about the product documentation which I believe Dexi folks can easily fix.
Octoparse
The blue Octo promises data at your fingertips with no programming at all and they’ve really got it. Within just 2 years of their launch, Octoparse has gone through 7 revised versions tweaking their scraping workflow with the feedback received from users. It’s got an intuitive point-and-click interface that supports infinite scrolling, log-in authentication, multi-format data export and supports unlimited pages per crawl in its free plan(yes, you heard that right!).
Pros:
- Scheduled crawling features and provision for unlimited web pages per crawl make it an ideal choice for price monitoring scenarios.
- Features provided in their free plan are more than enough if you are looking for an effective one-time, off-the-shelf solution with good user guide documentation. Also, precise extraction of data can be achieved with their in-built XPath and Regex tools.
Cons:
- Octoparse is yet to add pdf-data extraction and image extraction features (just image URL is fetched) so calling it a complete web data extraction tool would be a tall claim.
- Customer support is not great for the product and timely responses are not to be expected.
ParseHub
A desktop app that offers a graphical interface to select and extract the data of your choice from Javascript and AJAX pages as well and is supported by Windows, Mac OS X, and Linux. It can scrape through nested comments, maps, images, calendars, and pop-ups too. They’ve also got a browser-based extension to launch your scrape instantly and the tutorials out there are of great help.
Pros:
- ParseHub has a rich UI and pulls data from many tricky areas of a website, unlike other scrapers.
- Developers can play with ParseHub’s RestfulAPI for good data access after they are happy with the one-off scrape.
Cons:
- The purported free plan from ParseHub looks painful by limiting the number of scraped pages to 200 and just 5 projects in all. Plus, their paid versions begin at a whopping $149 per month which sounds way overboard especially for one-time scrapes.
- Speed at which scrape is performed needs to be vastly improved which also slows down the rate at which large volume scrape is done.
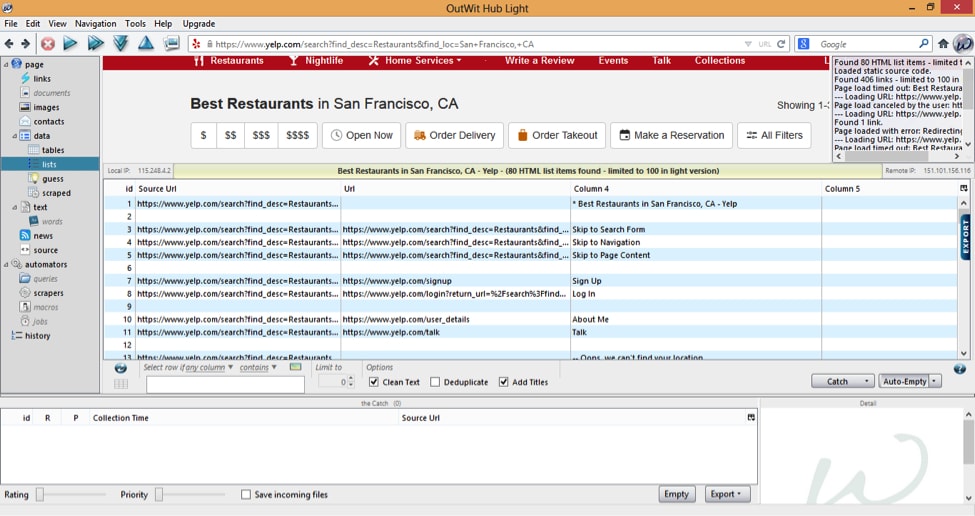
OutwitHub
Outwit technologies offers a simple, no-fancy GUI which was initially offered as a Firefox add-on (legacy version still available but with no feature updates) and now comes as a freely downloadable software that can be upgraded to Light and Pro version. With no programming skills, Outwit Hub can extract and export links, email addresses, RSS news and data tables to CSV, HTML, Excel or SQL databases. Their other products like Outwit Images and documents fetch images and docs from websites to your local drives.
Pros:
- It’s a flexible and powerful option for people looking to source contacts and is priced appropriately beginning at $69 for the basic one-time standalone application purchase.
- The “Fast Scrape” feature is a nice add to quickly scrape data from a list of URLs that you feed Outwit.
Cons:
- Outwit’s aptness for repeated, high volume scrapes is questionable and their documentation and tutorials definitely need a lift.
- The product lacks a point-and-click interface so first time users may need to go through random Youtube tutorials before their scrape venture.
FMiner
A visual web scraping software with a macro designer component to develop a scraping project flowchart by looking at the website alongside the same screen. The Python-based tool can be run on both Windows and Mac OS machines with good Regex support. FMiner has advanced data extraction features like captcha solving, post-extraction data refining options and allows you to embed python code to run tasks on target websites.
Pros:
Being multi-platform and a software feasible for both the no-code as well as the developer community, FMiner is powerful for data harvesting from complex site layouts.
Cons:
- The visual interface isn’t very appealing and efforts need to be put in to construct a proper scraping workflow (think flowcharts and connectors). You need to know your way around defining data elements with XPath expressions
- After a 15-day trial, you are forced to purchase at least the basic software version which is priced at $168 with no scheduling, email reporting or JS support. Btw, how active are they in keeping their product updated? Not so sure as there’s no news on recent improvements in FMiner.
Developer-Friendly Web scraping Tools
80Legs
Hosted on cloud and common scraping issues like rate limiting and rotating among multiple IP addresses taken care off (all in the free version!), 80Legs is a web crawling wonder! Upload your list of URLs, set the crawl limits, choose one of the pre-built apps from the versatile 80Legs app and you’re good to go. Example of an 80Legs app would be the Keyword app that counts the number of times the search term appears in all the listed URLs individually. Users are free to build their own apps and code which can be pushed into 80Legs making the tool more customizable and powerful.
Oh! And they’ve released a new version of their portal recently. Check it out.
Pros:
- Unlimited crawls per month, one crawl at a time for up to 10000 URLs right in the free version makes the 80Legs’ pricing plans an eyeful.
- Apps listed in 80Legs give a chance for users to analyze extracted web content and makes the tool a feasible option for the low-code skilled too.
Cons:
- Though support for huge web crawls is given, there are no basic data processing options provided which would be needed when such large-scale crawls are done.
- Advanced crawl features that coders might be interested in are not found in the 80Legs platform and their support team is found slow as well.
Content Grabber
Although touted as a visual point-and-click web scraping tool for non-coders, the complete potential of this tool can be tapped by folks with great programming skills leading to effective web scraping. Scripting templates are up for the grab to customize your scrapes and you can add your own C# or Visual Basic lines of code to it. Agent Explorer and XPath Editor provide options to group multiple commands and edit XPath as needed.
Pros:
- Developers have the freedom to debug the scraping scripts, log and handle the errors with inline command support.
- Large companies looking for a web scraping infrastructure can swear by Content Grabber for its robust and highly flexible scraping interface made possible by many advanced features found in the tool.
Cons:
- The software is available only for Windows and Linux, Mac OS users are advised to run the software in a virtual environment.
- Pricing is set at $995 for a one-time purchase of the software which puts it out of reach for simple and small scraping projects.
Mozenda
Targeted mostly at businesses and enterprises, Mozenda lets you create scraping agents which can be either hosted on Mozenda’s own servers or run in your system. Agreed that it has a nice UI to point-and-click but to develop the scraping agent, you need to spend time on tutorials and often get the help of their support team to construct an agent. That’s why categorizing it as a DIY tool for non-techies would be misleading. The robust tool can understand lists and complex website layouts along with XPath compatibility.
Pros:
- Mozenda’s agents scrape at a quick pace for scheduled and concurrent web scraping and support different site layouts.
- You can extract data in excel, word, PDF files and combine it with data sourced from the internet using Mozenda.
Cons:
Totally a Windows application and highly priced at an unbelievable $300/month for 2 simultaneous runs and 10 Agents.
Connotate
Connotate is a data extraction platform built exclusively for web data needs in enterprises. Though point-and-click is the method of data harvesting taken by Connotate, the UI and pricing are clearly not towards people with one-time scrape needs. Dealing with the schemas and maintaining the scraping agents needs trained people and if your company is looking for ways to collect information from thousands of URLs, then Connotate is the way to go.
Pros:
Connotate’s ability to deal with a huge number of dynamic sites along with its document extraction capabilities make the platform a viable option for large enterprises that utilize web data on a regular basis.
Cons:
Handling of errors during large-scale scrapes is not done smoothly which could cause a slight hiccup in your ongoing scraping project.
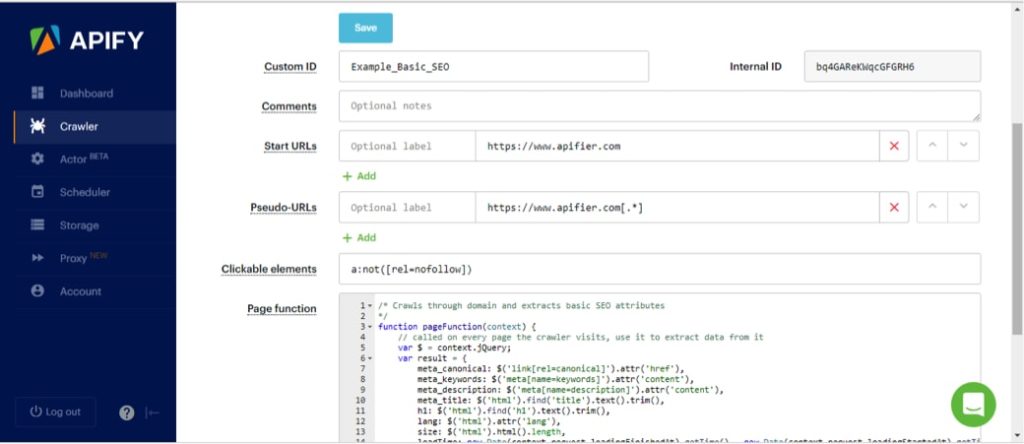
Apify
Apify, as the name indicates, is a web scraping platform for coders who want to turn websites into APIs. Cron-like scheduling of jobs and advanced web crawler features that support scraping of large websites is supported by Apify. They’ve got options for individual coders to enterprises to develop and maintain their APIs.
Pros:
- Apify has an active forum and community support enabling developers to reuse source codes hosted on GitHub and has an open library of specific scraping tools like SEO audit tool, email extractor, etc..
- API integrates with a huge number of apps and can handle complex pagination and site layout issues.
Cons:
As easy as it is for developers to write a few lines of Javascript, handling IP rotation and proxies would be their prime challenge which goes unaddressed directly in Apify.
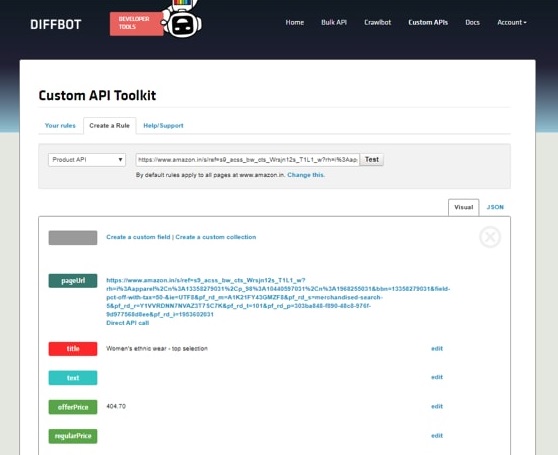
Diffbot
Another web scraping software taking the API route of accessing web data, Diffbot incorporates ML and NLP techniques to identify and sort web content. Developers can create their custom APIs to analyze content on blogs, reviews and event pages. Diffbot extends a library of these APIs that makes it easy to choose and integrate the API of your choice.
Pros:
Their ML-based algorithm to identify and classify the type of web content delivers an accurate extraction of the data.
Cons:
Human-like understanding of documents are yet to be brought in and Diffbot is on the expensive side of scraping the web too.
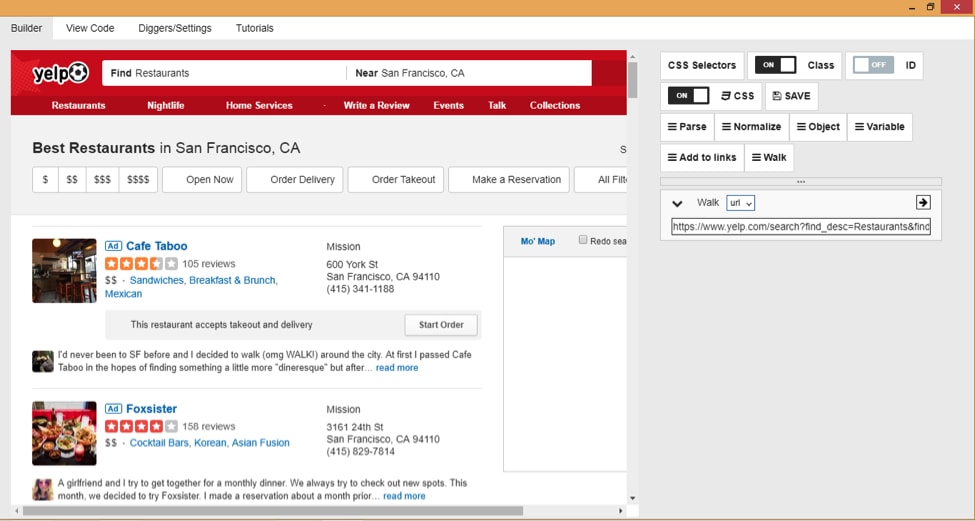
Diggernaut
‘Turn website content into datasets’ goes the claim on the Diggernaut homepage along with a ‘no-programming skills required’ tag. But the cloud-based extraction tool that comes as a chrome extension and as a standalone desktop application, has the meta-language feature that allows coders to automate difficult scraping tasks with their own code. An understanding of HTML, CSS/JQuery, and YAML markup languages are needed to configure their diggers.
Pros:
- Diggernaut comes with a pretty cool OCR module that can help you pull data from images.
- There’s also an option for developers to build restful APIs to easily access web data, all at very affordable rates – their free version supports 3 diggers and 5K page requests.
Cons:
In the point-and-click genre, Diggernaut is a little difficult to understand at first. Also, when image extraction features are quite slick it hurts to see no document extraction modules.
Wrapping up
Web scraping tools are available in plenty out there and they work like a charm for one-off scrapes, small-time scraping hobbies and routine scrapes that have an in-house team of professionals dedicated for its maintenance. And there’s always the effort that you have to spend on cleaning and enriching the output data.
Whenever you find the pricing or basic handling and maintenance of the web scraping tools going way over your head, you can always turn to reliable web data aggregation services like those offered by Mobius that’ll smoothly take care of all the hard web data chores.
Wondering why we didn’t include one of your all-time favorite web scraping tools? Drop in your own scraping star in the comment section below.
This article was originally published on KDnuggets.

Ida Jessie Sagina
Content Marketing Specialist
Read AI-generated summary
- Ever since machine learning and data science took the world by storm, researchers and businesses alike are on the lookout for more data and the hunt for data is on from unconventional data sources like the Internet.
- Being an extremely curious data scientist or an entrepreneur high on innovation, you don’t want to lose out on the growth opportunities lying untapped in the public web.
- DIY Point-and-click web scraping tools for the no-coders – To the self-confessed non-techie with no coding knowledge, there’s a bunch of visually appealing point and click tools that help you build sales list or populate product information for your catalog with zero manual scripting.
- Outsourcing the entire web scraping project – For enterprises that look for extensively scaled scraping or time-pressed projects where you don’t have a team of developers to put together a scraping solution, web scraping services come to the rescue.
- Monitoring website changes and the ability to integrate with a number of reporting tools and apps make it a great option for enterprises with a pressing scraping need.


 systems")
